More than 80% of data is recorded in an unstructured format. Unstructured data will continue to increase with the prominence of the internet of things. Data is being generated from audio, social media communications (like posts, tweets, messages on WhatsApp etc) and in various other forms. The majority of this data exists in text form, which is highly unstructured in nature.
In order to produce significant and actionable insights from text data, it is important to get acquainted with the techniques and principles of Natural Language Processing (NLP).
What Is NLP?
Massive amounts of data are stored in text as natural language, however some of it is not directly machine understandable. The ability to process and analyse this data has huge scope in our current business and day to day lives. However, processing this unstructured kind of data is a complex task.
Natural Language Processing (NLP) techniques provide the basis for mobilising this massive amount of data and making it useful for further processing.
A few examples of NLP that people use every day are:
- Spell check
- Autocomplete
- Voice text messaging
- Spam filters
- Related keywords on search engines
- Siri, Alexa, or Google Assistant
Natural Language Processing Tasks
- Tokenisation: This task splits the text roughly into words depending on the language being used. These tokens help in understanding the context or developing the model for the NLP. The tokenisation helps in interpreting the meaning of the text by analysing the sequence of the words.
- Sentence boundary detection: This task involves splitting text into sub-sentences by a predefined boundary. This boundary could be a new line or a regular expression that will match something to be treated as a sentence boundary (eg: ., !, ?, <p>,<html> etc ) or you may specify the whole document to be defined as the sentence.
- Shallow parsing: This next task involves classifying words within a sentence (nouns, verbs, adjectives, etc.) and links them to higher order units that have discrete grammatical meanings (noun groups or phrases, verb groups, etc.).
- Stemming and Lemmatisation: For grammatical reasons, documents are going to use different forms of a word, such as write, writes and writing. Additionally, there are families of derivationally related words with similar meanings, such as democracy, democratic, and democratisation. In many situations, it would be useful if a search for one of these words would return documents that contain another word in the set. For example, when searching for ‘democracy’, results containing the word ‘democratic’ are also returned. The goal of both stemming and lemmatisation is to reduce inflectional forms and sometimes derivationally related forms of a word to a common base form.
- Named-entity Recognition: To automatically identify named entities within raw text and classify them into predetermined categories, like people, organisations, email addresses, locations, values, etc.
- Summarisation: The art of creating short, coherent and accurate content based on vast knowledge sources. This could be articles, documents, blogs, social media or anything over the web. For example, in the news feed, summarisation of sentences for news articles.
Python for Natural Language Processing (NLP)
There are many things about python that make it a really good programming language choice for an NLP project. The simple syntax and transparent semantics of this language make it an excellent choice for projects that include Natural Language Processing tasks. Moreover, developers can enjoy excellent support for integration with other languages and tools that come in handy for techniques like machine learning.
But there’s something else about this versatile language that makes it such a great technology for helping machines process natural languages. It provides developers with an extensive collection of NLP tools and libraries that enable developers to handle a great number of NLP-related tasks and it has a shallow learning curve, its syntax and semantics are transparent, and it has good string-handling functionality.
When it comes to natural language processing, Python is a top technology. Developing software that can handle natural languages in the context of artificial intelligence can be challenging. But thanks to this extensive toolkit and Python NLP libraries, developers get all the support they need while building amazing tools.
The 6 libraries of this amazing programming language make it a top choice for any project that relies on machine understanding of unstructured data.
- Natural Language Toolkit (NLTK) - Its modularised structure makes it excellent for learning and exploring NLP concepts.
- TextBlob - TextBlob is built on top of NLTK, and it’s more easily accessible. This is one of the preferred libraries for fast-prototyping or building applications that don’t require highly optimised performance.
- CoreNLP - CoreNLP is a Java library with Python wrappers. It’s in many existing production systems due to its speed.
- Gensim - Gensim is most commonly used for topic modelling and similarity detection. It’s not a general-purpose NLP library, but for the tasks it does handle, it does them well.
- spaCy - SpaCy is a new NLP library that’s designed to be fast, streamlined, and production-ready. It’s not as widely adopted, but if you’re building a new application, you should give it a try.
- scikit–learn - Simple and efficient tools for predictive data analysis. Built on NumPy, SciPy, and matplotlib.
Why Python?
Python is a simple yet powerful programming language with excellent functionality for processing linguistic data. Python is heavily used in industry, scientific research, and education around the world. Python is often praised for the way it facilitates productivity, quality, and maintainability of software. A collection of Python success stories is posted at Python Success Stories.
NLTK defines an infrastructure that can be used to build NLP programs in Python. It provides basic classes for representing data relevant to natural language processing; standard interfaces for performing tasks such as part-of-speech tagging, syntactic parsing, and text classification; and standard implementations for each task that can be combined to solve complex problems.
Word Count Program Using NLTK Python
Install following packages using pip:
pip install nltk
# You can use NLTK on Python 2.7, 3.4, and 3.5
pip install bs4
# Python library for pulling out of HTML and XML files
pip install html5lib
pip install lxml
# Python libraries for parsing HTML and xml
python -m nltk.downloader stopwords
# Download the default stopwords Ref: https://gist.github.com/sebleier/554280
# Alternatively you can create your own list of stopwords and use in the program
pip install matplotlib
# Python library for creating static, animated and interactive visualizationsFirst, Import necessary modules:
import nltk
import urllib.request
from bs4 import BeautifulSoup
from nltk.corpus import stopwordsSecond, we will grab a webpage and analyse the text.
Urllib module will help us to crown the webpage:
url_response = urllib.request.urlopen('https://en.wikipedia.org/wiki/Computer_science')
html_response = url_response.read()Next, we will use BeautifulSoup library to pull data out of HTML and XML files and clean the text of HTML tags.
html_soup = BeautifulSoup(html_response,'html5lib')
html_text = html_soup.get_text(strip = True)Till this point, we have a clean text from the HTML page, now convert the text to tokens.
tokens = [t for t in html_text.split()]Further pieces of code will remove all stop words and count the word frequency.
clean_tokens = tokens[:]
for token in tokens:
if token in stopwords.words('english'):
clean_tokens.remove(token)
freq_count = nltk.FreqDist(clean_tokens)In the final part, we will display the top 50 common words with count and plot the data on a map.
print (freq_count.most_common(50))
freq_count.plot(10, cumulative=False)Sample Output
(nlp) bash-3.2$ python wordcount.py
[('computer', 97), ('Computer', 51), ('science', 47), ('The', 27), ('Science', 22), ('p.', 18), ('computers', 17), ('first', 16), ('information', 16), ('one', 16), ('software', 15), ('Computing', 15), ('computing', 14), ('articles', 13), ('study', 13), ('used', 13), ('science,', 13), ('data', 13), ('engineering', 12), ('University', 11), ('also', 10), ('design', 9), ('academic', 9), ('often', 9), ('field', 9), ('1', 9), ('language', 8), ('development', 8), ('many', 8), ('became', 8), ('new', 8), ('methods', 8), ('using', 8), ('&', 8), ('different', 7), ('theoretical', 7), ('practical', 7), ('computational', 7), ('In', 7), ('mathematical', 7), ('research', 7), ('scientific', 7), ('areas', 7), ('programming', 7), ('Archived', 7), ('fromthe', 7), ('History', 7), ('computation', 6), ('question', 6), ('fields', 6)]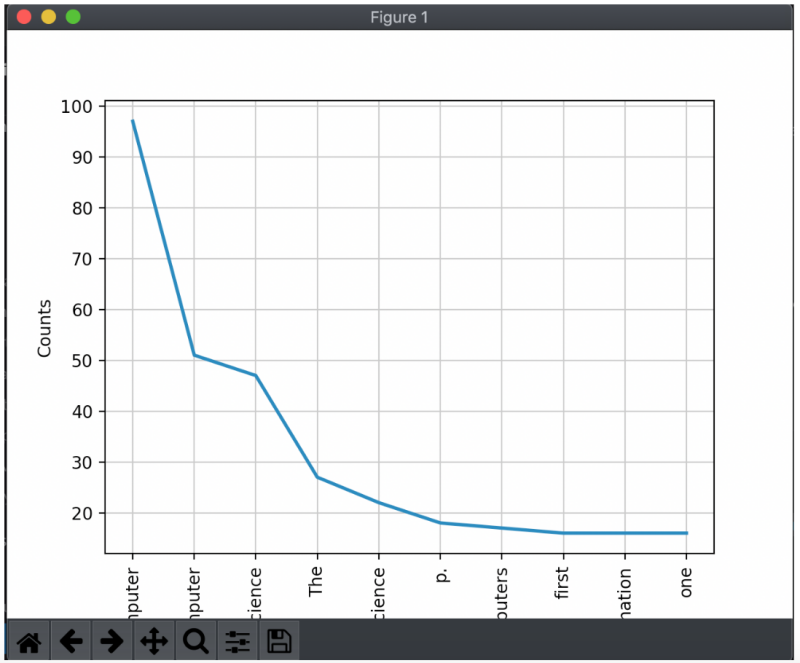
Pros and Cons of NLTK
Pros:
- Most well-known and full NLP library with many 3rd extensions
- Supports the largest number of languages compared to other libraries
Cons:
- Difficult to learn
- Slow
- Only splits text by sentences, without analysing the semantic structure
- No natural network models