
In my previous job, we built a large enterprise management system with a web front-end and a relational back-end. Something that became apparent early in the design was that we had a lot of data that was fundamentally hierarchical. Be it on the Human Resources side, where we had to represent the organisational structure, or on the safety side, where we had injured parts of the body or underlying causes of incidents; a lot of the data was naturally tree-like (and we rendered it as such in the client).
Lots of requests back and forth to the database were not an option due to performance constraints of the network (think high latency, low bandwidth, third world), so we needed to query this hierarchical data in a single efficient hit prior to rendering it in whatever manner was needed. We also used this hierarchical information extensively in our security model to determine which users could see information about other users based on their relative position(s) in the organisation. This required relatively complex comparisons of trees to be performed quickly. The size of some of the datasets – and our need to often only work with partial trees – meant that returning the entire result-set and playing with it recursively in the application server was not an efficient option.
This post covers how to (simply) store hierarchical data in a relational database and query it in a high-performance manner using standard SQL-99 features (without traversing trees one record – and one query – at a time or resorting to stored procedures).
Common Table Expression
Now before we get into the detail of trees and querying them, we need to take a brief diversion into an SQL Construct called a Common Table Expression, or CTE. This is a temporary resultset that is defined within the execution scope of a single SELECT, INSERT, UPDATE, DELETE, or CREATE VIEW statement, which persists only for the duration of the query.
The CTE typically takes the basic form below:
WITH cte_name AS (
a_select -- an SQL Expression
),
another_cte_name AS (
b_select -- an SQL Expression
)
SELECT *
FROM cte_name;a_select and b_select would, of course, be replaced by SQL SELECT statements in an actual example. The above example shows two queries (a_select and b_select) in the WITH section, but only one is necessary (and there is no specific limit to how many you can have). In this case, the results of a_select are available to b_select and also to the final “outer” query. The results of b_select are available to the outer query.
In the form above, the CTE does not provide any additional functionality beyond that which could be achieved using sub-queries. Its main advantage is the improved readability gained from breaking a large multi-level query up into smaller named components. This is especially so if the same sub-query would ordinarily be repeated multiple times; you can just refer to the CTE wherever you need it in the outer query (and as many times as you need to).
Here is a contrived example (that requires no actual tables)
WITH values_list AS (
SELECT * FROM (VALUES (1, 'One'), (2, 'Two'), (3, 'Three'), (4, 'Four'), (5, 'Five')) AS t(num, name)
)
SELECT name
FROM values_list
WHERE num % 2 = 0 -- Even numbers
UNION SELECT name
FROM values_list
WHERE num % 2 != 0 -- Odd numbersThis returns the following rows. As can be seen, we used the common expression, values_list twice in our outer query (but we only had to define it once).

Right, we’ll come back to CTEs in the next section, with some concrete examples related to trees.
Tree Representation
Firstly, how can we generally represent the tree structure in our RDBMS? Well, fortunately trees are about the simplest data structure known to man (discovered shortly after fire and sliced bread), so all that is required is to have each node of the tree have a parent_id that points to the next node up. For our example, let’s have a simple table of corporate positions within an organisation, with the evil three-letter overlords at the top, the B-Ark passengers in the middle, and the hard working faceless stalwarts at the bottom:
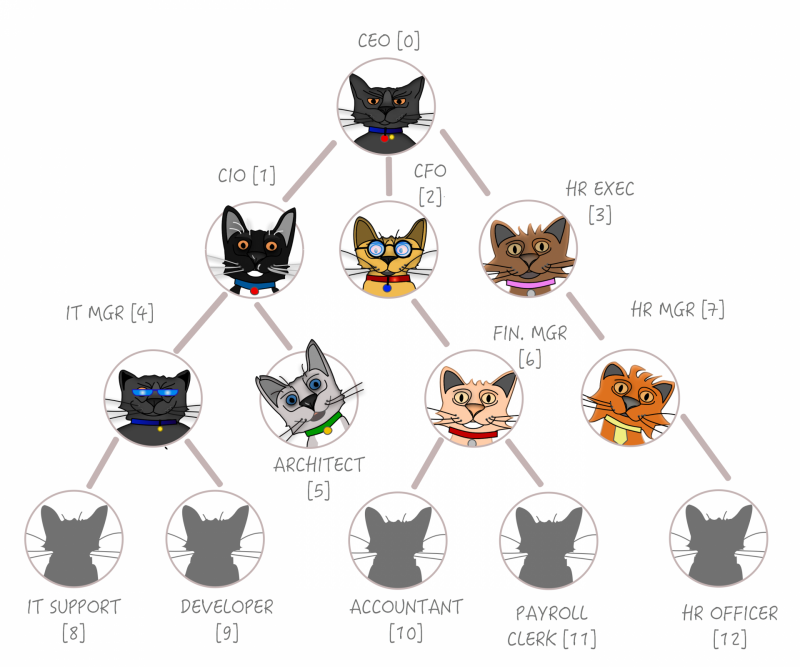
A database representation using a single table and Foreign Key Constraint might look something like this:
CREATE TABLE org_position (
id serial PRIMARY KEY NOT NULL,
parent_id integer,
name varchar NOT NULL
);
ALTER TABLE org_position ADD CONSTRAINT “$1” FOREIGN KEY (parent_id) REFERENCES org_positThis tree has no implied ordering within each parent from left to right. It has to be said, this isn’t the only way of representing a tree in the database, but it is by far the simplest, and it makes it very simple to re-parent sections of the tree.
Querying a Node and All It’s Children
In order to get a node and descendent nodes, we can use another variant of the CTE. This time, we introduce an extra keyword, RECURSIVE. A recursive (although in reality, it is iterative) CTE is more than just syntactic sweetener – it gives you capabilities that other types of query do not have.
WITH RECURSIVE cte_name (column_names) AS (
initial_select
UNION
recursive_select
)
SELECT *
FROM cte_name;Essentially, the RDBMS executes the initial_select, and stores the result in a temporary resultset. It then repeatedly executes the recursive_select on the temporary resultset, each time replacing contents of the temporary resultset with the results of the query. This process only ends when the recursive_select returns an empty set (i.e. no rows). At that point, the entire temporary resultset is made available to the “outer” select to do with as it pleases. It is important that the recursive_select does eventually return an empty set or the query will iterate forever (or at least until you hit the maximum query time you have defined in your postgresql.conf).
The example below shows how to get Node 2 (“CFO”) and all of its children (and children’s children) using this technique:
WITH RECURSIVE children AS (
SELECT id, parent_id, name
FROM org_position where id = 2
UNION
SELECT tp.id, tp.parent_id, tp.name
FROM org_position tp
JOIN children c ON tp.parent_id = c.id
)
SELECT *
FROM children;This returns the following rows:

Querying the Depth Associated With Each Node
If we also want to get the depth of each of the nodes relative to the first node, that is a simple addition to the query, as shown below:
WITH RECURSIVE children AS (
SELECT id, parent_id, name, 1 as depth
FROM org_position
WHERE id = 2
UNION
SELECT op.id, op.parent_id, op.name, depth + 1
FROM org_position op
JOIN children c ON op.parent_id = c.id
)
SELECT *
FROM children;This returns the following rows:

Querying the Parents of a Node
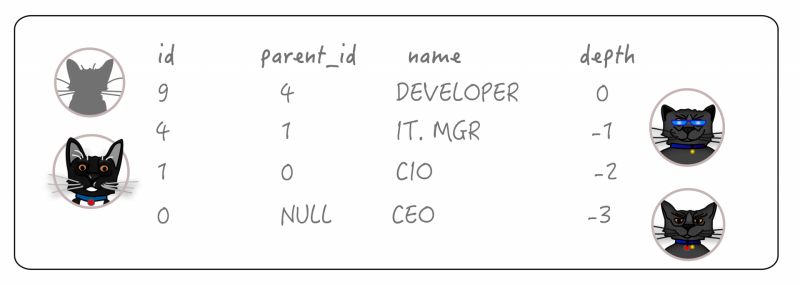
If we wish to work our way up the tree towards the root node, rather than down towards the leaves, we can do this by altering the join condition accordingly. For example, everything including and above Node 9 (“Developer”):
WITH RECURSIVE parents AS (
SELECT id, parent_id, name, 0 as depth
FROM org_position
WHERE id = 9
UNION
SELECT op.id, op.parent_id, op.name, depth - 1
FROM org_position op
JOIN parents p ON op.id = p.parent_id
)
SELECT *
FROM parents ;Note that the “depth + 1” was changed to “depth – 1” so that the relative depth of each parent node would be an integer one less then its child. This was a fairly arbitrary choice, and you might want to do it differently!
This returns the following rows:
Connect By – An Alternative Approach
An alternative mechanism for querying tree structures is to use the CONNECT BY statement (or connectby in PostgreSQL). CONNECT BY is a standard feature of ORACLE RDBMS, but is not part of the PostgreSQL core functionality, and instead, it is included in the tablefunc Additional Supplied Module.
Assuming your PostgreSQL install has access to tablefunc, you can install its functions into your database with:
CREATE EXTENSION tablefunc;
The format of connectby is:
connectby(text relname, text keyid_fld, text parent_keyid_fld [, text orderby_fld ], text start_with, int max_depth [, text branch_delim ])
To reproduce our example of getting node 2 and all its children:
select pt.*
FROM connectby('org_position'::text, 'id'::text, 'parent_id'::text, 1::text, 0)
AS t(keyid int , parent_keyid int, level int)
JOIN org_position pt on pt.id = t.keyidSo why would you potentially use connectby, rather than WITH RECURSIVE? You would probably only use it where you already had legacy code that you wished to remain consistent with. Some limited testing of a slightly more complex tree containing 4,000+ records seems to show performance that is in favour of the RECURSIVE CTE approach (550ms vs 850ms). Testing was by no means exhaustive, and your mileage may vary.
For more information, head over to the excellent documentation at postgresql.org.
Banner image: Photo by Subtle Cinematics on Unsplash










